AI inference is deployed to enhance consumer lives with smart, real-time experiences and to gain insights from trillions of end-point sensors and cameras. Compared to CPU-only servers, edge and entry-level servers with NVIDIA A2 Tensor Core GPUs offer up to 20X more inference performance, instantly upgrading any server to handle modern AI.
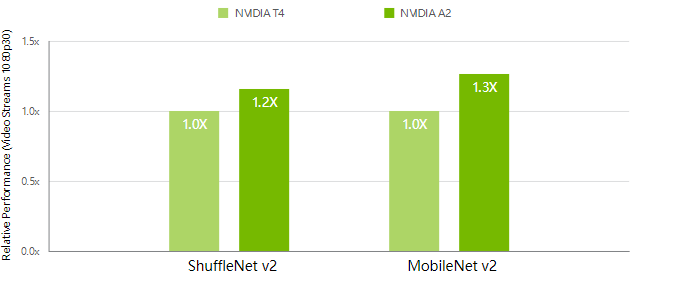
The NVIDIA A2 Tensor Core GPU provides entry-level inference with low power, a small footprint, and high performance for NVIDIA AI at the edge. Featuring a low-profile PCIe Gen4 card and a low 40-60W configurable thermal design power (TDP) capability, the A2 brings versatile inference acceleration to any server for deployment at scale. Comparisons of one NVIDIA A2 Tensor Core GPU versus a dual-socket Xeon Gold 6330N CPU System Configuration: [CPU: HPE DL380 Gen10 Plus, 2S Xeon Gold 6330N @2.2GHz, 512GB DDR4] Servers equipped with NVIDIA A2 GPUs offer up to 1.3X more performance in intelligent edge use cases, including smart cities, manufacturing, and retail. NVIDIA A2 GPUs running IVA workloads deliver more efficient deployments with up to 1.6X better price-performance and 10 percent better energy efficiency than previous GPU generations. System Configuration: [Supermicro SYS-1029GQ-TRT, 2S Xeon Gold 6240 @2.6GHz, 512GB DDR4, 1x NVIDIA A2 OR 1x NVIDIA T4] | Measured performance with Deepstream 5.1. Networks: ShuffleNet-v2 (224x224), MobileNet-v2 (224x224). | Pipeline represents end-to-end performance with video capture and decode, pre-processing, batching, inference, and post-processing. NVIDIA A2 is optimized for inference workloads and deployments in entry-level servers constrained by space and thermal requirements, such as 5G edge and industrial environments. A2 delivers a low-profile form factor operating in a low-power envelope, from a TDP of 60W down to 40W, making it ideal for any server.
1pcs New NVIDIA TESLA A2 16GB Graphics Card, high bracket
Versatile Entry-Level Inference
Up to 20X More Inference Performance
NLP: BERT-Large (Sequence length: 384, SQuAD: v1.1) | TensorRT 8.2, Precision: INT8, BS:1 (GPU) | OpenVINO 2021.4, Precision: INT8, BS:1 (CPU)
Text-to-Speech: Tacotron2 + Waveglow end-to-end pipeline (input length: 128) | PyTorch 1.9, Precision: FP16, BS:1 (GPU) | PyTorch 1.9, Precision: FP32, BS:1 (CPU)
Computer Vision: EfficientDet-D0 (COCO, 512x512) | TensorRT 8.2, Precision: INT8, BS:8 (GPU) | OpenVINO 2021.4, Precision: INT8, BS:8 (CPU)
Higher IVA Performance for the
Intelligent Edge
IVA Performance (Normalized)
Optimized for Any Server
Lower Power and Configurable TDP

TECHNICAL SPECIFICATIONS